|
|
| (One intermediate revision by one user not shown) |
| Line 9: |
Line 9: |
| | == Terminology == | | == Terminology == |
| | In parsing lingo a ''symbol'' is a name in a grammar. Each symbol is either a ''terminal'' or a ''non-terminal''. Non-terminals appear on the left hand side of a grammar production; terminals don't. | | In parsing lingo a ''symbol'' is a name in a grammar. Each symbol is either a ''terminal'' or a ''non-terminal''. Non-terminals appear on the left hand side of a grammar production; terminals don't. |
| − |
| |
| − | == Issues Discussed ==
| |
| − | Around this design we constructed a variety of patterns and discussed them.
| |
| − | === Patterns in Use ===
| |
| − | * DTSTTCPW Design
| |
| − | === Downcasting vs No-ops vs [[DBC]] based superclasses ===
| |
| − | === Data Redundancy ===
| |
| − | === Test Driven Development & Refactoring ===
| |
| − |
| |
| − | == Possible Solutions ==
| |
| − | === Standard Composite Solution ===
| |
| − |
| |
| − | [[image:parse-tree-sol-basic-composite.png]]
| |
| − |
| |
| − | * Important methods are declared in the abstract Node class
| |
| − | * The client can deal entirely with Nodes
| |
| − | * The client must accept a very loose contract provided by the Node class. For example the add() method may or may not add.
| |
| − | * The client must check the class type of the object if this contract is insufficient.
| |
| − | * This design may be suitable if we are only reading from this structure. If this is the case we can interpret the no-ops in Token as meaning Token has no children. From this perspective the no-ops are not necessarily a hack as they semantically make sense.
| |
| − |
| |
| − | ==== Violations ====
| |
| − | * [[Avoid no-op overrides]]
| |
| − |
| |
| − | === Wal's Solution ===
| |
| − |
| |
| − | [[image:parse-tree-sol-wals.png]]
| |
| − |
| |
| − | * Moves the definition of important methods down to BranchNode to avoid the need for no-ops.
| |
| − | * The contract defined for the important methods in BranchNode can promise more.
| |
| − | * Also avoids the need for Downcasting by as*() methods defined in Node
| |
| − | * This means the Node class must be aware of it's own subclasses.
| |
| − |
| |
| − | ==== Violations ====
| |
| − |
| |
| − | * [[Dependency inversion principle]]
| |
| − |
| |
| − | === Wal's Solution Refactored ===
| |
| − |
| |
| − | [[image:parse-tree-sol-wals-refactored.png]]
| |
| − |
| |
| − | * Some Tokens don't require the text field, as their text is defined by their type. For example the text of a "SemiColon" Token is always ";".
| |
| − | * This redundancy is removed by applying [[Extract Subclass]] which adds the ValueToken class
| |
| − |
| |
| − | ==== Violations ====
| |
| − | * [[Avoid concrete base classes]]: Correcting this would add a [[Lazy class smell]]
| |
| − |
| |
| − | == Implementation of Language ==
| |
| − | I started thinking about how to use the [[Flyweight]] pattern with the implementation for the actual language we developed last Monday. Since I didn't take any notes (duh!) I tried to come up with something be myself but it doesn't really convince me. I recall the diagram on the board being way bigger than mine. However, I see that diagram as a starting point for next class. Maybe there are some correct aspects and at least I learned something about patterns ... :) --[[User:TobiW|TobiW]] 01:20, 13 August 2009 (UTC)
| |
| − |
| |
| − | [[Image:ParseTreeFlyweight01.png]]
| |
| − |
| |
| − | == See Also ==
| |
| − | * [[Avoid no-op overrides]]
| |
| − | * [[Beware type switches]]
| |
| − | * [[Decorator]]
| |
| − | * [[Refactoring]]
| |
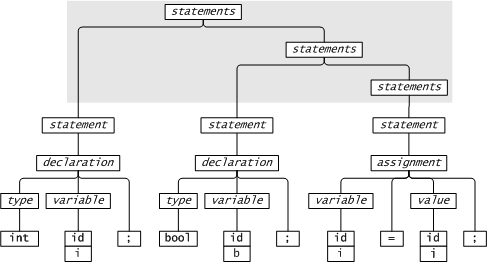
A context free grammar defines a language, e.g.
A parse tree shows how a sentence in the language is structured according to the grammar.